I wrote 39,000+ words across 223 entries in my diary in the last 1.5 years. Could I learn more about my mood/emotions by analyzing my diary? I wrote some Python to find out. (skip to results)
The data
Diary entries are usually emotive and abstract. Below I describe an approach to quantifying my mood over the last 1.5 years. This dataset consists of diary entries written either when I was attending college or working full-time. All of my diary entries share the following properties:
- Time of last update (for example:
January 10th, 2018, at 7:20pm) - Name of entry (for example:
happy-to-see-you.txt) - Text content (the actual entry)
Sentiment analysis
I quantify the content of each diary entry by its sentiment: how positive or negative I felt in each entry. Sentiment analysis is an approach to automatically identifying opinions/feelings in a text. My pipeline has 3 steps, all using some subset of numpy, pandas, and matplotlib.
- Data cleanup. I filter out stop words. In natural language processing, stop words are tokens like
a,of,the. These common words are syntactically important for language, but they carry little information and aren’t useful for sentiment analysis. - Lookup sentiment in the Emotion Lexicon. The NRC Word-Emotion Association Lexicon maps an index of 14,000+ words to eight basic emotions: anger, fear, anticipation, trust, surprise, sadness, joy, and disgust. I simply look up a word in the Emotion Lexicon and retrieve its associated emotion, for all 39,000 words in my diary.
- Classify sentiment with
word2vec. Many words in my diary aren’t catalogued in the Emotion Lexicon, so I trained a classifier usingword2vecandsklearn.linear_model.LogisticRegressionto identify the sentiment of almost all the remaining words.
Results
Overview
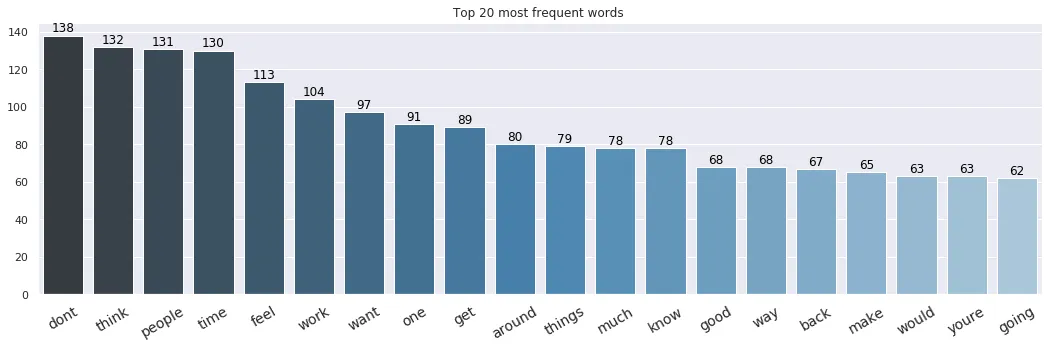
Like most people, I usually write about myself or other people. Since we filtered out stop words, common but relatively meaningless tokens like on, for, etc. are omitted. Below are the top 20 words which occur most frequently in my diary, dominantly concerning topics like thinking and people.
Most of my diary entries are under 200 words. The most significant outlier, at 3,278 words, is about distractions and a short attention span. At bottom left, I bin diary entries based on word count. At bottom right, the horizontal axis is the time domain, and each point represents 1 of my 223 diary entires (with the 3,278-word outlier on Nov 2018).

Weekly trends
I write the most on the weekends. As the week progresses, I spend more time studying/working, and consequentially less time writing. On Saturdays, I apparently unload all that’s accumulated during the week.

Compared to the mean, on Thursdays (my most negative day) I’m more negative by a delta of 4.7%. Sorry to everyone I hung out with on Thursdays. As expected, positive and negative sentiment are inversely related and tend to settle at a more positive mood during the weekend.

The NRC Word-Emotion Association Lexicon lets us look at other emotions too. As shown below, throughout the week I consistently anticipate the arrival of the weekend. Similarly, sadness achieves a maximum in the middle of the business week, then steadily declines as we approach the weekend. That seems consistent with reality:

Long-run trends
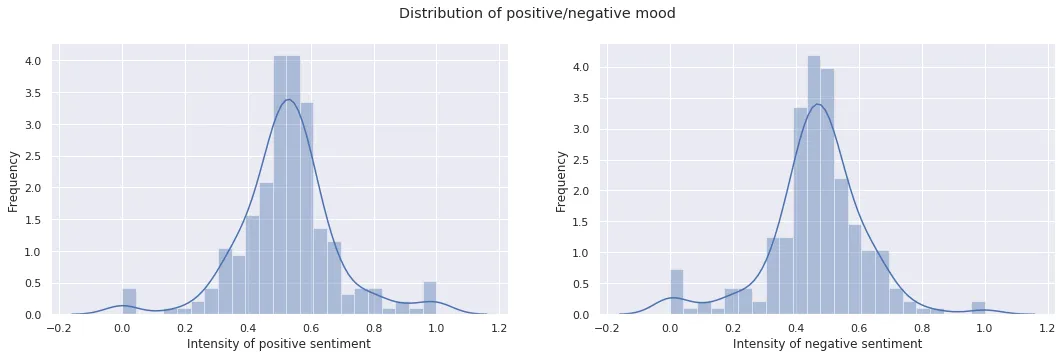
As approximate metrics of mood, the intensity of positive and negative sentiment are both normally distributed. Negative sentiment has a slightly left-skewed distribution, with a long-tail on the left. Sentiment is normalized to the length of each diary entry.
Below I show the total sentiment (positive sentiment - negative sentiment) expressed in my diary. This provides a rough metric of positive (sentiment>0) or negative (sentiment<0) mood. Total sentiment takes a value between -1.0 and +1.0. Over 1.5 years my mood (as measured by positive/negative sentiment) has steadily tended towards more positive sentiment. I take the rolling mean of each sentiment score over a 1-week, 1-month, and 3-month window:

Mood in the past 1.5 years as measured by total sentiment is fairly volatile, with standard deviation 0.298 for sentiment in the range -1.0 to 1.0. 95% of diary entries have a total sentiment score that lies within 2 standard deviations of the mean sentiment (consistent with the normality of the distribution of positive and negative sentiment).
If my mood (as measured by sentiment) reverts to the mean, then even when sentiment drifts towards the positive or negative extreme I can expect it to settle back towards the mean. Knowing whether mood is mean-reverting might allow me to reduce the stress I experience during periods of negative mood. We can test whether mood is reverts to the mean in the long run with a quick stationarity test. Using the augmented Dickey-Fuller test (statsmodels.tsa.adfuller), we find that total sentiment is mean-reverting (p<0.05).
Conclusions
Based on my diary, my mood as measured by total sentiment is mean-reverting and most positive during the weekends but otherwise fairly volatile. None of this analysis offers a concrete statement about my mood, though, since the approach is crude and my approach fails to capture some relevant information.
In summary I didn’t learn much from this, and I’ve got a lot of statistics to review. But the graphs are pretty, right?